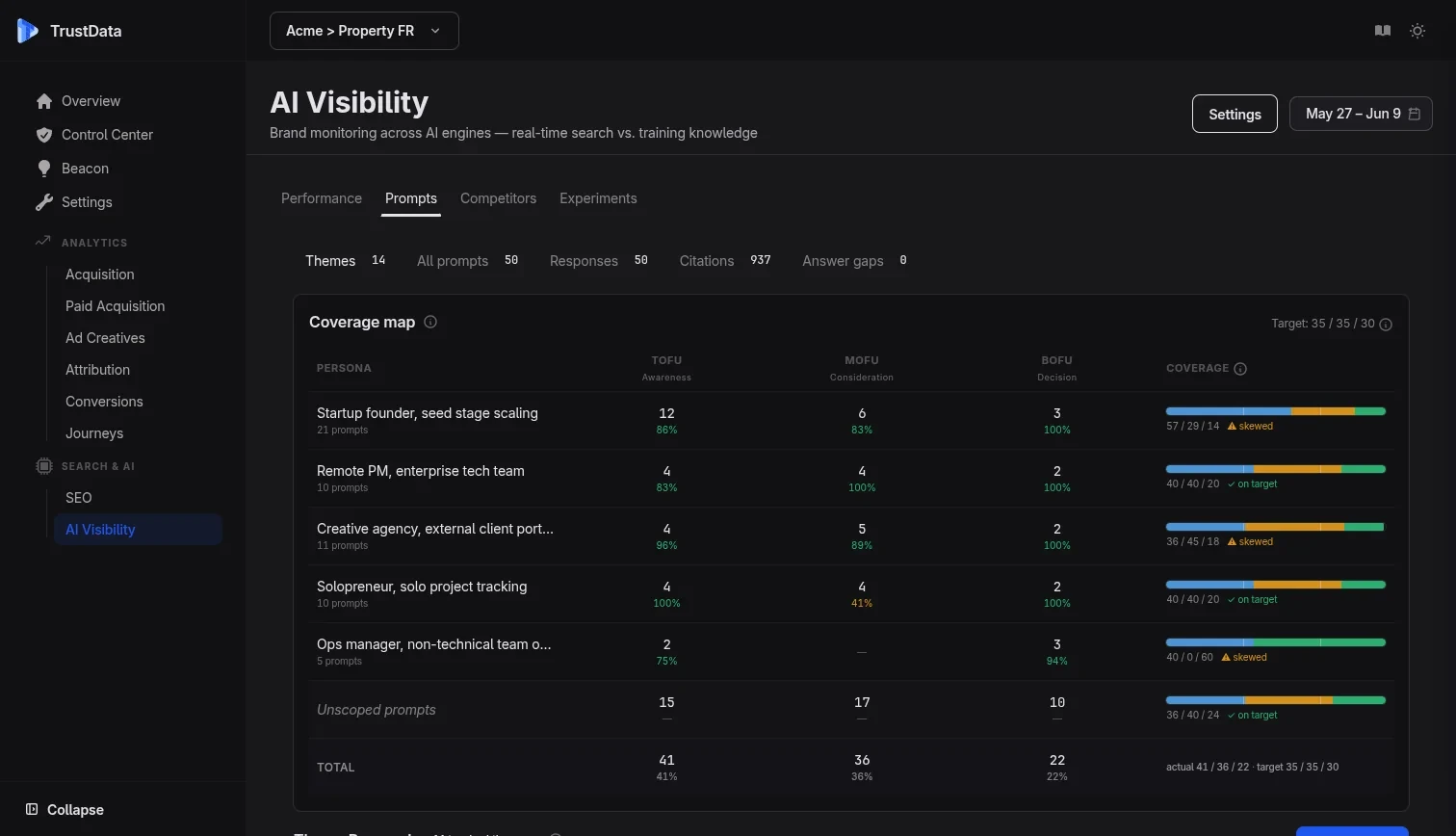
Four prompt types per engine
Brand direct, category, comparison, and pain point queries. Each maps to a different stage of the buying journey and requires different content strategies to win.
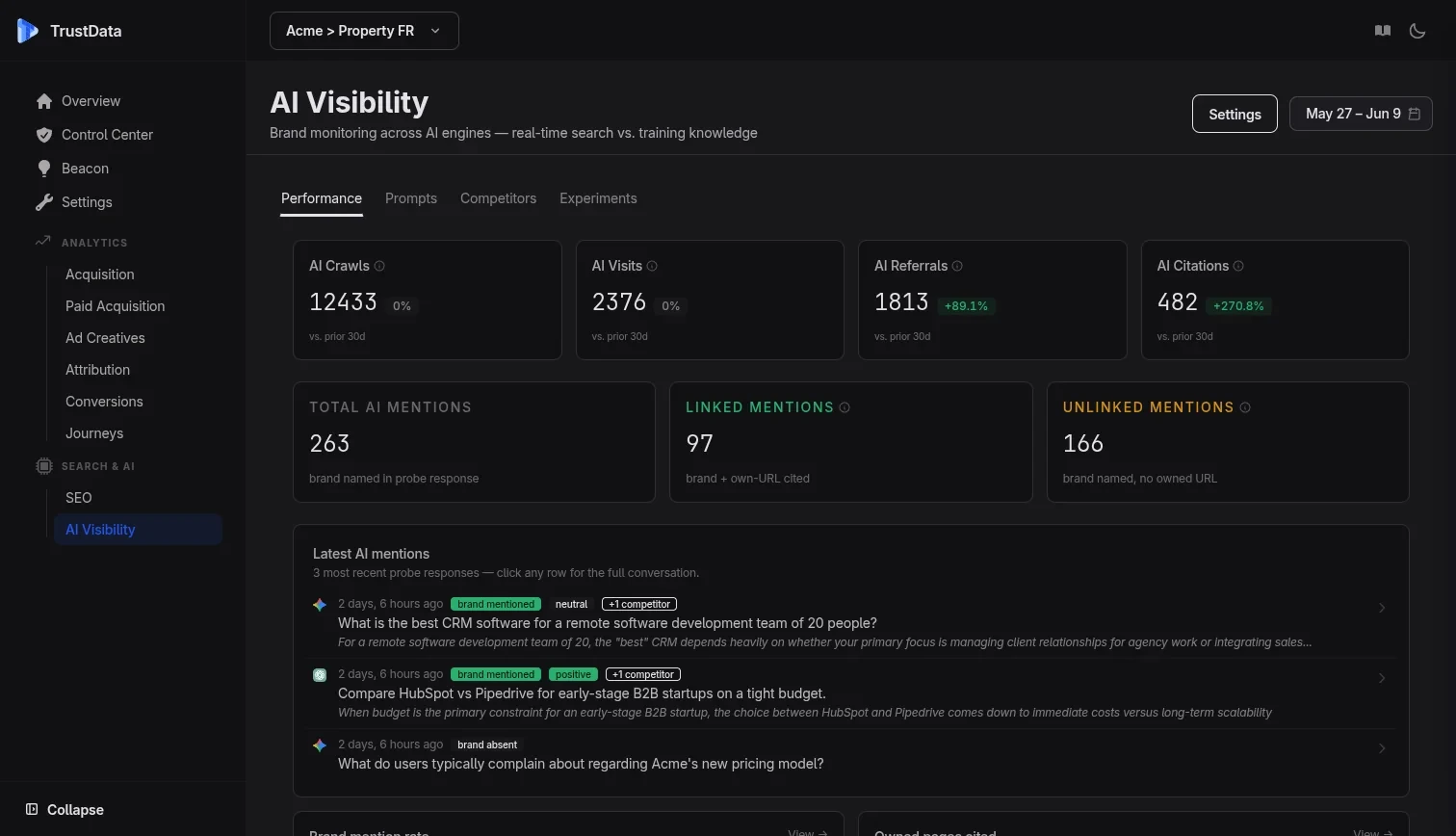
LLM brand monitoring
We send automated prompts to ChatGPT, Gemini, Claude, Perplexity, Mistral, Grok and DeepSeek every day, with and without web search, across four query types.
Brand direct, category, comparison, and pain point queries. Each maps to a different stage of the buying journey and requires different content strategies to win.
Probes run in two modes, with real-time web search and without. The gap between them reveals whether your brand exists in LLM training data or only in recent web indexes.
A 0–100 composite score across all engines and prompt types. Weighted 60% with-search, 40% no-search to reflect real-world AI answer behavior.
Share of voice
TrustData tracks which competitors appear alongside (or instead of) your brand in AI-generated answers and quantifies your share of voice across every engine and query type.
Add competitor names once. TrustData automatically matches them in every probe extraction and tracks their mention rate alongside yours.
Side-by-side breakdown of your brand vs top 5 competitors. See which engine and which prompt type you're winning or losing, and by how much.
Each probe extraction classifies your brand's sentiment as positive, neutral, or negative. A high mention rate with negative sentiment is worse than not being mentioned.
AI Search analytics
Most monitoring tools track upstream signals in isolation. We measure AI Search referral sessions in your first-party analytics, so you see how much traffic AI engines actually drive and how it converts.
Identify sessions from AI Search referrals (ChatGPT, Perplexity, Gemini) in your first-party data. Track their conversion rate vs organic search across ~50 AI domains tracked server-side.
Your pages are either optimized for AI extraction or they're invisible. TrustData crawls your site, scores pages for AI readability, and shows you exactly what to improve.
All measurement runs on your deduplicated first-party data, never on platform-reported numbers. No black box. No guessing.
Experiment engine
Most AI presence advice is untestable. We turn every content change into a measurable experiment, with a natural control group built from your own probe schedule.
Every recommendation includes a testable hypothesis: "If we add FAQ schema to the comparison page, our mention rate on comparison queries should improve because…
When a change targets comparison queries, your brand_direct and category probes run unaffected on the same schedule. Their mention rate drift is the natural control.
After 7+ days, TrustData calculates the adjusted delta: treatment rate change minus control rate change. Verdict thresholds (winner, likely winner, inconclusive, no effect) are calibrated to your probe sample sizes.
Every component of the AI Visibility layer.
7 engines: ChatGPT, Gemini, Claude, Perplexity, Mistral, Grok, and DeepSeek, with and without real-time web search.
0–100 composite score updated daily. Weighted mention rate across all engines, all prompt types. Returns null if fewer than 5 probes (prevents noise from small samples).
14-day rolling mention rate with current vs prior 7-day comparison. Trend direction (rising/declining/stable) shown as an alert signal.
Brand vs competitor mention rate per engine and prompt type. Competitors managed via a simple slug list; TrustData handles fuzzy matching in extraction.
Positive / neutral / negative sentiment classified by Mistral extraction for each mention. Aggregated across the last 14 days.
After following a recommendation, TrustData checks whether the target URL appears in AI probe citations. A citation match alongside a mention rate lift strengthens the winner verdict.
AI Search referral sessions, CVR, traffic share, and AI Overview impressions, all from your first-party tracking, compared against prior period.
Followed recommendations tracked for 7+ days. Adjusted delta (treatment minus control). winner / likely_winner / inconclusive / no_effect thresholds.
FAQ
14-day free trial
14-day free trial. AI Visibility monitoring included in every tier: ChatGPT, Gemini, Claude, Perplexity, Mistral, Grok, and DeepSeek.